Novità dell'architettura Sandy Bridge - 1
Intel ha introdotto alcune novità architetturali nella CPU, nulla di radicale come avvenuto con l’Intel Core 2 o con l’architettura Nahalem ma sufficiente a garantire miglioramenti prestazionali e di efficienza consistenti. Analizziamoli brevemente, senza soffermarci troppo sui dettagli e sulle implicazioni tecniche, che esulano dallo scopo di questa recensione.
ADVANCED VECTOR EXTENSION, NUOVO SET DI ISTRUZIONI PER OPERAZIONI IN FLOATING POINT
Intel, in collaborazione con AMD ha sviluppato un nuovo set di istruzioni per applicazioni multimediali e finanziarie estendendo il set SSE4 a 128 bit, con un set di istruzioni a 256bit più versatile e in grado di ospitare fino a 3 operandi, con il registro di destinazione dell’operazione che può essere diverso dal registro sorgente e dal registro dell’operando. Questo permette operazioni non distruttive ovvero in cui il registro sorgente rimante invariato dopo il compimento dell’operazione, il dato viene infatti salvato sul terzo registro. Per esprimerci più chiaramente invece di eseguire l’istruzione a=a+b, si potrà eseguire c=a+b, mantenendo in memoria entrambi gli operandi. Questo permetterà di minimizzare i caricamenti in cache, permettendo di riutilizzare entrambi gli operandi. Da non sottovalutare inoltre la possibilità di effettuare operazioni su vettori più grandi, grazie alle istruzioni di dimensioni doppia. Queste istruzioni ovviamente devono essere supportate via software, quindi potranno essere sfruttate soltanto nei software più recenti che le implementano. Ci auguriamo una rapida adozione, vista anche la futura compatibilità anche con le CPU Bulldozer, che AMD si appresta a lanciare nel giro di qualche mese.
Il grande vantaggio ottenuto da Intel in Sandy Bridge è stato la possibilità di aggiungere questo set di istruzioni senza dovere ampliare notevolmente l’area necessaria ad ospitare nuove unità per l’esecuzione delle stesse.
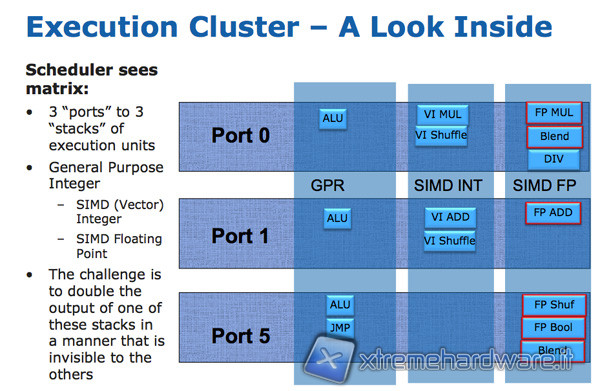

In primo luogo, infatti, Intel ha sfruttato la struttura a matrice del cluster di esecuzione, caratterizzato da 3 porte e 3 stack a 128 bit, per eseguire anche le istruzioni AVX a 256bit, semplicemente combinando i due datapath a 128 bit delle unità SIMD per gli interi e delle unità SIMD per le istruzioni Floating Point.
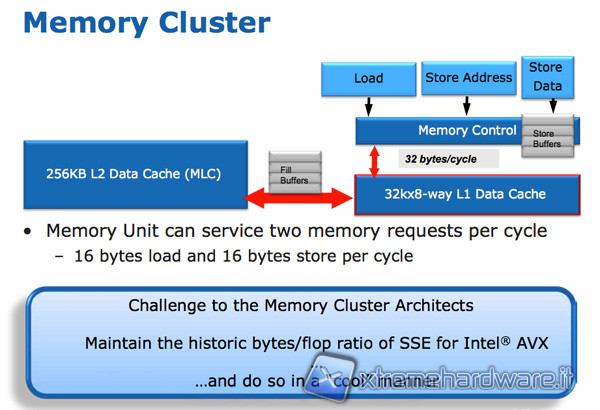
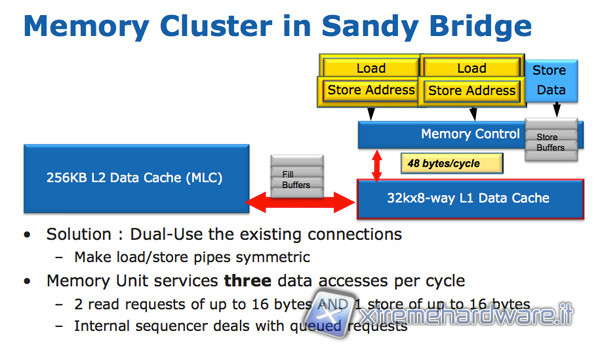
Per bilanciare la maggiore potenza computazionale in Floating Point, le CPU Sandy Bridge necessitano di un accesso alla memoria più efficiente. Anche questa volta Intel sfrutta l’architettura preesistente che prevede tre porte di tipo Load/Store: Load, Store Address e Store Data. Con un design simmetrico delle porte Load e Store Address, che sono ora in grado di compiere entrambe le operazioni, è possibile caricare il doppio di dati per ciclo di clock.
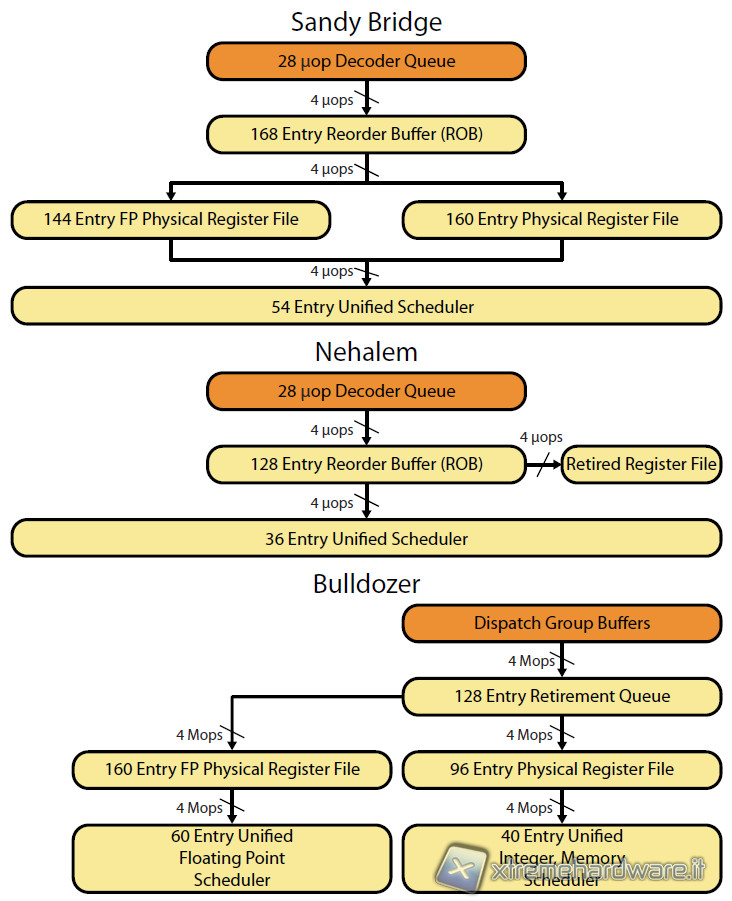
PHYSICAL REGISTER FILE
Il passaggio alle istruzioni AVX sarebbe stato impossibile senza una modifica del Cluster che si occupa dell’esecuzione Out of Order delle istruzioni, ovvero di quella unità che si occupa del riordino delle istruzioni in modo da massimizzare l’efficienza nell’esecuzione delle stesse. In particolare Intel ha introdotto i Physical Register File (PRF) che permettono di memorizzare direttamente gli operandi delle micro-operazioni in modo definitivo nel registro, senza bisogno di far viaggiare l’operando in diverse parti della CPU. Il PRF ha permesso ad Intel di risparmiare una buona area di silicio oltre che ridurre i consumi dell’unità di esecuzione out of order. Il risparmio di area è stato bilanciato con l’aumento dei Buffer di Load e Store, e della dimensione dello Scheduler e del Buffer di Reorder (ROB).

L’adozione dei PRF è presente anche nell’architettura Bulldozer di AMD, ma in Bulldozer troviamo uno scheduler separato per operazioni in Floating Point e per operazioni su Interi.
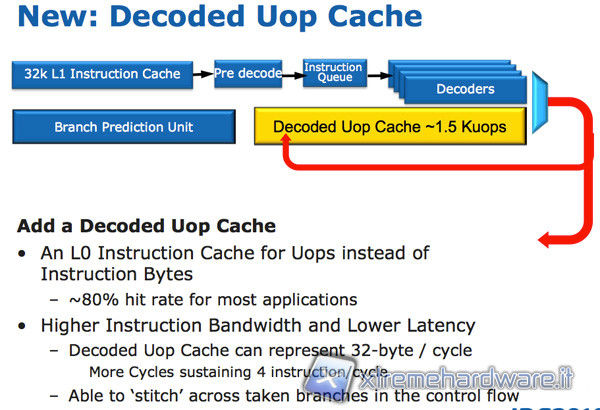
MICRO-OP CACHE
Un’altra interessante novità dell’architettura Sandy Bridge è una cache per le micro-operazioni decodificate dalle istruzioni complesse. Questa cache può contenere 1,5K di micro-operazioni equivalenti praticamente a una cache aggiuntiva per le istruzioni di 6KB. Questa cache permette di aumentare notevolmente l’efficienza del front-end della CPU, ovvero quella che prepara le istruzioni più semplici per essere calcolate dalle unità di esecuzione. L’incremento prestazionale è più evidente nel codice con molti salti condizionali e interruzioni, in cui le istruzioni complesse necessitano di essere ri-decodificate, rallentando tutto il front-end. Intel dichiara per molte applicazioni un hit rate nella uop-cache dell’80%, consentendo ogni volta un boost rilevante rispetto ad un accesso in cache L1.