NVIDIA annuncia oggi il progetto di integrare un'interconnessione ad alta velocità, denominata NVIDIA® NVLink™, nelle sue future GPU, per consentire a GPU e CPU di condividere i dati fino a 12 volte più velocemente di quanto possano fare oggi. Questo eliminerà i colli di bottiglia e contribuirà ad aprire le porte verso una nuova generazione di supercomputer exascale, che saranno 50-100 volte più veloci dei sistemi più potenti di oggi.
NVIDIA includerà la tecnologia NVLink nella sua architettura GPU Pascal, che è attesa per il 2016 e che farà seguito all'architettura NVIDIA Maxwell presentata quest'anno. La nuova interconnessione è stata sviluppata insieme a IBM, che la integrerà nelle versioni future delle sue POWER CPU.
“La tecnologia NVLink sprigiona il pieno potenziale della GPU, migliorando in modo significativo il trasferimento dei dati tra CPU e GPU, minimizzando i tempi in cui la GPU deve attendere i dati da processare.", ha dichiarato Brian Kelleher, Senior Vice President, GPU Engineering, di NVIDIA.
“NVLink consente un veloce scambio di dati tra CPU e GPU, migliorando, quindi, il flusso dei dati e superando il collo di bottiglia che rappresenta il problema dell'accelerated computing di oggi.”, ha affermato Bradley McCredie, Vice President & IBM Fellow di IBM. “NVLink facilita gli sviluppatori nel modificare le applicazioni per sfruttare i benefici dei sistemi accelerati da CPU-GPU nell'ambito del data analytics ad alte performance. Crediamo che questa tecnologia rappresenti un ulteriore e importante contributo per il nostro ecosistema OpenPOWER.”
Con la tecnologia NVLink, che unisce strettamente le POWER CPU di IBM con le GPU NVIDIA Tesla®, l'ecosistema per data center POWER sarà in grado di sfruttare pienamente l'accelerazione su GPU per diverse applicazioni, tra cui l'high performance computing, il data analytics e il machine learning.
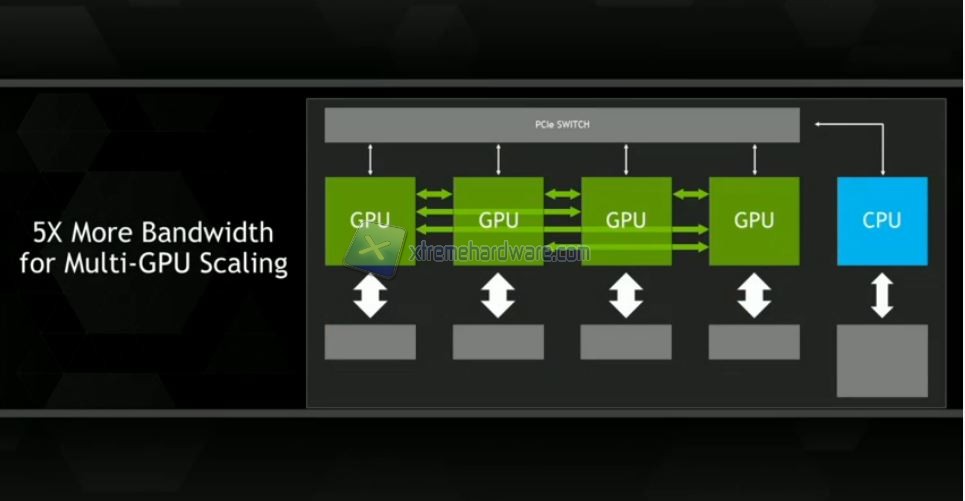
Vantaggi rispetto al PCI Express 3.0
Oggi le GPU sono connesse alle CPU x86 tramite interfaccia PCI Express (PCIe), che limita la capacità della GPU di accedere alla memoria della CPU e che è da quattro a cinque volte più lenta dei tipici sistemi basati su CPU. PCIe rappresenta un collo di bottiglia ancora più grande tra la GPU e le CPU IBM POWER, che dispongono di una quantità maggiore di banda delle CPU x86. Quando l'interfaccia NVLink soddisferà la larghezza di banda tipica dei sistemi CPU, sarà possibile per le GPU accedere alla memoria delle CPU sfruttando appieno la loro larghezza di banda.
Questa interconnessione high-bandwidth migliorerà enormemente le prestazioni delle applicazioni. Poiché le GPU dispongono di memo memoria ma più veloce, mentre le CPU hanno più memoria, ma più lenta, le applicazioni tipicamente muovono i dati dalla rete o dal disk storage verso la memoria della CPU e poi copiano i dati nella memoria della GPU prima che possano essere processati. Con NVLink, i dati si muovono tra la memoria della CPU e la memoria della GPU con velocità molto maggiori, rendendo le applicazioni accelerate da GPU molto più veloci.
Unified Memory
Il trasferimento più veloce dei dati, in coppia con la Unified Memory, semplificherà la programmazione su GPU. Unified Memory consente al programmatore di considerare le memorie di CPU e GPU come un unico blocco di memoria. Il programmatore può operare sui dati senza preoccuparsi se risiedono nella memoria della CPU o della GPU.
Sebbene le future GPU NVIDIA continueranno a offrire supporto al PCIe, la tecnologia NVLink sarà utilizzata per connettere le GPU alle CPU in grado di supportare questa interfaccia e assicureranno connessioni con un'elevata larghezza di banda direttamente tra le GPU multiple. Inoltre, pur a fronte di un'elevata larghezza di banda, NVLink è sostanzialmente più efficiente sul piano energetico (per bit trasferito) rispetto all'interfaccia PCIe.
NVIDIA ha progettato un modulo per ospitare le GPU basate su architettura Pascal con NVLink. Questo nuovo modulo GPU sarà di dimensioni pari a un terzo della misura delle schede PCIe standard utilizzate per le GPU. I connettori in fondo al modulo Pascal gli consentono di essere collegato alla scheda madre, migliorando il design del sistema e l'integrità del segnale.
L'interconnessione a elevata velocità NVLink consentirà ai sistemi "accoppiati" di funzionare a 1.000 petaflop (1 x 1018 floating point operations per second), ovvero da 50 a 100 volte più velocemente dei sistemi attualmente più performanti.
Press Release